



TL;DR — A working LLM-as-a-judge prompt has four parts in this order: a criterion definition in your domain's vocabulary, an explicit reasoning structure that forces a claim-by-claim or step-by-step check, a scoring rule that maps the reasoning result to a deterministic verdict, and a clause that handles the edge cases your retrieval or agent pipeline actually produces. Skip any of the four and the judge falls back to plausibility checks, which is what makes generic prompts miss the failures that matter. The templates below cover faithfulness, relevance, format compliance, and agent tool correctness — the four criteria most production pipelines need first.
This piece is for engineers who have already built or used a judge and want a prompt that survives a calibration run, not a starter snippet. If you have not yet built the pipeline the judge sits inside, start with the complete guide and come back.
The four-part structure of a working judge prompt
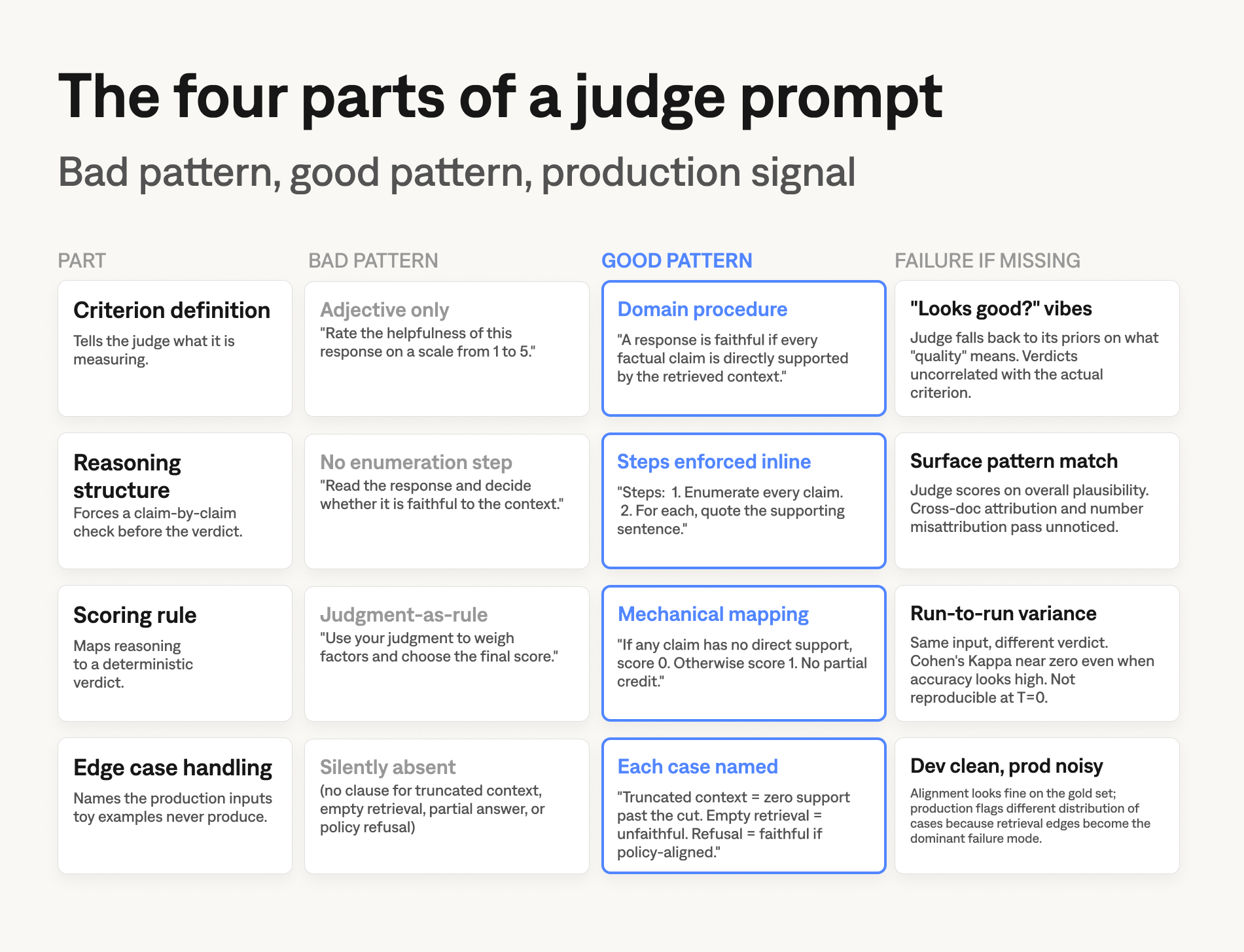
The complete guide names the four elements at a glance. This piece is the version with the failure mode each one prevents, and the bad-vs-good rewrite for each. A judge prompt is a small program written in English that the model executes against a specific input. The four parts below are load-bearing. Removing any of them changes the behaviour in production, not just on the dev set.
Criterion definition. Write the criterion in the words your domain uses, not in generic ML vocabulary. "Every factual claim in the response is directly and explicitly supported by the retrieved context" is a domain definition. "The response is high quality" is not a definition; it is a placeholder that the judge will fill in with whatever its priors happen to be. If your team disagrees on what the criterion means, that disagreement is what the prompt has to settle. Vague rubrics produce vague verdicts at scale.
Reasoning structure. Tell the judge to enumerate the discrete units of evaluation before assigning a score. Chain-of-thought reasoning only helps when the judge is enumerating the right units; what matters at the prompt level is specifying exactly what those units are. Claims for faithfulness. Intents for relevance. Tool calls plus arguments for agent grading. Required and prohibited elements for format compliance. Without an enumeration step, the judge runs surface-level pattern matching: does this response look like a faithful response? With one, the judge runs the check you actually want: is each claim supported, yes or no?
Scoring rule. Map the reasoning result to a verdict with a deterministic rule. "If any enumerated claim is not directly supported by the retrieved context, score 0" is a rule. "Use your judgment to weigh the overall faithfulness" is not. The point of the scoring rule is to remove judgment from the scoring step; the judgment goes into the reasoning structure, the score is mechanical. This is what makes runs reproducible at temperature 0.
Edge case handling. Production retrieval pipelines produce inputs that toy examples never do. Truncated context at chunk boundaries. Empty retrievals when the query falls outside the index. Partial answers. Refusals. Multi-turn responses where part of the answer is faithful and part is not. Spell out how the judge should treat each one. Truncated context counts as zero support for anything past the cut. Empty retrievals make every external claim unfaithful by definition. A refusal is faithful if the refusal itself is supported by policy. Without these clauses, the judge will fall back to plausibility and score them however the model is biased.
Rubric design patterns that survive production
Rubric design is where most of the gains in judge quality actually live. The same model with the same criterion definition can score 0.40 alignment or 0.75 alignment against the same gold labels, depending on how the rubric is structured.
Pick the lowest-precision scale that captures the distinction you care about. Binary pass/fail when the question is "did the response violate the rubric, yes or no." Three-point (fail / partial / pass) when degrees of failure matter for triage. Only go to 1-to-5 or 1-to-10 if you have the gold-set data to validate that the judge can use the resolution. Fine-grained scales invite the judge to invent distinctions it cannot defend, and the resulting noise eats the signal. In our experience and the published results from MT-Bench, binary judges align with humans more reliably than 5-point judges on the same task. The 5-point judge gives you more numbers, not more information.
One rubric per dimension. A single prompt that scores faithfulness, relevance, fluency, and format compliance in one pass produces correlated, unreliable scores. The model anchors on the first dimension and lets that anchor bleed into the others. Score one criterion at a time, in separate calls, and average or aggregate at the application layer. The cost of an extra inference call is small compared to the cost of being unable to attribute a regression to a specific dimension.
Operationalise fuzzy criteria. "Helpful" is a feeling, not a rubric. "The response directly addresses every constraint in the user's query, including the negative constraints" is a rubric. If you find yourself writing an adjective in the rubric ("helpful," "accurate," "professional"), replace it with the procedure a human evaluator would actually perform to determine whether the adjective applies. The judge will execute the procedure; it will not execute the adjective.
Build in length neutrality. A rubric that does not explicitly say "concise responses score equal to or better than verbose ones at equivalent correctness" is a rubric that implicitly optimises for length. Verbosity bias is a measurable property of LLM judges: given responses of equivalent quality, judges consistently score longer answers higher. Any "completeness" or "thoroughness" reward needs an explicit upper bound, or the judge will treat longer answers as more thorough by default.
Expect the rubric to drift. Shankar et al. (2024) documented criteria drift: human evaluators routinely revise the criteria after seeing model outputs. A rubric written upfront is a hypothesis, not a final artefact. Treat it like code: version it, track which gold labels were produced under which version, and recalibrate after material edits.
Worked example: faithfulness judge for RAG
Faithfulness is the highest-value criterion to get right because it is the failure mode that costs the most in production. A judge that misses faithfulness failures is one that ships hallucinations with confidence. The template below extends a minimal faithfulness prompt in two ways: an unsupported_claims list in the output schema, and explicit reasoning steps that handle the implicit-claim and empty-retrieval cases most baselines miss.
The non-obvious bits are worth naming. The judge enumerates before scoring, not after; reversing the order lets the model commit to a verdict and rationalise it backwards. The output schema asks for unsupported_claims as a list, which forces the judge to either populate the list or admit there is nothing in it. This catches the most common failure mode in faithfulness judging: cross-document attribution, where the response contains a fact that is true elsewhere but not in the retrieved passage. A judge that only returns {"verdict": "unfaithful", "reason": "..."} will paper over this; a judge that has to list the specific unsupported claims will surface it.
The case where this template still misses things is when the unsupported claim is implicit in a longer construction ("the refund window is generous" when the context specifies a number but not an adjective). For implicit claims, add a step in the reasoning structure: "if the response uses an evaluative or comparative phrase about a quantifiable property, the underlying quantity must appear in the context." See how a calibration loop finds these gaps automatically in the judge optimization guide.
Worked example: relevance judge for RAG and chat
Relevance asks a different question than faithfulness. Faithfulness checks whether the response stays inside the retrieved evidence; relevance checks whether it answers what the user actually asked. A response can be perfectly faithful and completely irrelevant, quoting an unrelated paragraph from the context verbatim. It can also be relevant and unfaithful.
The classic failure mode for naive relevance prompts is that they reward topical similarity. The query is "what is the refund window for unused subscriptions?" and the response describes the subscription tiers in detail without mentioning a refund window. A judge that scores on topical overlap will pass this. A judge that scores on intent coverage will not.
Two things this template gets right that generic relevance prompts do not. First, the decomposition step is mandatory and the schema enforces it: the judge cannot return a verdict without listing the intents and marking each one. Second, negative constraints are called out explicitly, because they are the most common silent failure. A response that handles four out of five intents and ignores the negative constraint ("not X") will read as relevant to a judge that scans for topic match.
The combination of a faithfulness judge and a relevance judge covers the two failure axes of a RAG response: a faithful but irrelevant answer is the system retrieving the wrong context; an unfaithful but relevant answer is the model fabricating beyond the context. Both need to be caught, and one judge cannot do both jobs without conflating them.
Worked example: format compliance judge
Format compliance is the criterion where an LLM judge is most likely to be the wrong tool, and where teams use it anyway. If your output is supposed to be valid JSON against a schema, a deterministic schema check is faster, cheaper, and more reliable than any judge. Run pydantic or jsonschema first. The judge handles the cases the schema cannot.
Where a judge does add value: semi-structured output where the structure is loosely defined (e.g., "a numbered list of three to five recommendations, each with one supporting sentence"), partial compliance where the schema passes but the content violates an implicit rule, or natural-language output that should follow a style guide (citation format, tone, redaction of personally identifiable information).
The explicit "do not evaluate aspects not listed above" clause matters. Without it, a format judge will start grading on relevance and faithfulness too, because the model wants to be helpful, and the scores from this judge will end up correlated with the scores from the other two judges. The correlation breaks alignment with humans and makes it impossible to diagnose which dimension is regressing.
Compose this judge with a deterministic schema check upstream. The pipeline is: schema check → if pass, run the format judge for the soft requirements → if pass, run the content judges. Each step gates the next, and you only pay for the LLM call when the deterministic check has already cleared.

Worked example: agent tool correctness judge
Agent evaluation has a different shape than RAG evaluation. The unit of analysis is a trajectory: every tool call the agent made, with arguments and results, plus the final response. Three sub-criteria sit inside "tool correctness," and conflating them produces a judge that cannot distinguish between failure modes.
Tool selection. Did the agent call the right tools for the user's request? An agent that calls search_kb when it should have called query_database is making a selection error.
Argument correctness. Did the agent populate the tool arguments correctly? An agent that calls query_database(start_date="2024-01-01") when the user asked about "last week" is making an argument error, even if the tool itself was the right choice.
Trajectory coherence. Did the sequence of calls make sense? An agent that calls the same tool three times with identical arguments, or that retrieves data and then ignores it in the response, is making a trajectory error.
Score these as three separate judges, not as one mega-judge. The reasoning structures are different, and a single rubric will end up with the model hedging across the three concerns.
Tool-correctness judging is a place where Galtea encodes the pattern as a first-class metric: the Tool Correctness metric takes the captured trajectory from the @trace decorator and scores selection, arguments, and ordering against an expected trajectory. The reason to use a built-in metric here rather than rolling the judge yourself is that the trace capture is the hard part, the judge prompt is the easy part, and the two need to share a schema.
For multi-step agents with branching trajectories, the comparison-to-expected approach breaks down because there is no single correct trajectory. In those cases, the rubric shifts from "did the agent match the expected path" to "did each step have a justification consistent with the prior state," which is a different prompt and a different evaluation problem. A later piece in this series covers trajectory-grading for open-ended agents.
Common ways judge prompts fail in production

Five anti-patterns show up in almost every judge prompt that has not been calibrated. The fixes are not subtle.
Vague rubric language. "Rate the response on a scale from 1 to 5, where 5 is excellent and 1 is poor." The judge will produce a number. The number will not mean anything across runs. The fix is to define what each level on the scale corresponds to in terms of an observable property of the response.
Over-specifying the verdict format. The problem with long structured rationales before the verdict is specific enough to name. Asking the judge for "first analyse X, then consider Y, then weigh Z, then produce a final paragraph of reasoning, then return the score" does not just cost tokens. The rationale is generated token by token, and the early tokens commit the model to a direction before it has thought about the problem; everything that follows is post-hoc justification anchored on the first sentence. Keep the reasoning structure inside the prompt, not inside the output.
Implicit length preference. If the rubric rewards "thoroughness," "depth," or "completeness" without bounding them, the judge will prefer longer responses. Either bound those criteria explicitly or add a length-neutrality clause.
"Use your judgment" anywhere in the prompt. This phrase is a signal that the rubric is incomplete. The judge will use its judgment; what its judgment looks like is exactly what calibration is trying to measure. Replace every instance with a deterministic rule.
Mixing the generator's instructions into the judge's instructions. Copy-pasting the system prompt from the generator into the judge ("you are a helpful, honest assistant...") makes the judge score responses against the generator's persona rather than against the rubric. The judge has one job: apply the rubric. Strip everything else.
Evaluating the prompt itself, not just the model
A judge prompt that looks reasonable on three examples will produce different verdicts on the next thirty. The way to find out before the prompt goes anywhere near production is to score it against a labelled gold set and measure alignment with the human labels. Aggregate accuracy is not enough; report Cohen's Kappa, per-class recall, and at least one rank-based metric (Spearman) so that imbalanced gold sets do not flatter the prompt.
The full calibration loop, the seven-metric ensemble, and a production case where this approach moved a faithfulness judge from 0.40 to 0.75 alignment in nine human annotations is covered in detail in the judge optimization guide. The thing to keep in mind while writing the prompt is that the prompt is a hypothesis, not a deliverable. It will need to be measured, rewritten, and re-measured before it can gate a deploy.
Inside Galtea, judge prompts are versioned alongside the LLM-as-a-judge metric they belong to, and each metric version is bound to the gold set it was calibrated against. The reason to version judges this way is not bookkeeping; it is that an alignment regression after a prompt edit needs to be attributable to the edit, and a regression after a model release needs to be attributable to the model. Without versioning, the two get conflated and you lose the ability to diagnose which one drifted.
When NOT to write a custom judge prompt
Three cases where a custom prompt is the wrong move, and where teams write one anyway.
When a deterministic check covers the criterion, do not write a judge prompt for it. SQL equivalence, JSON schema validation, regex match, and tool-call argument matching against a known-good trajectory all have closed-form answers. An LLM judge is the wrong tool entirely in these cases; the prompt-design implication is sharper. The calibration cycle you would spend on a custom prompt (write rubric, label gold set, run optimisation, re-measure) never pays back, because the underlying question is not ambiguous. Writing the prompt is itself the waste.
When the criterion is well-served by a published, calibrated judge prompt, use that one. The Galtea-documented faithfulness, relevance, and tool-correctness prompts have been calibrated against multiple gold sets across customer deployments. Starting from a calibrated baseline and editing against your specific failure modes is faster than starting from scratch.
When the team has not yet built a gold set, do not write a custom prompt yet either. Calibration without a gold set is not calibration. Write the gold set first, run a stock prompt against it to establish a baseline, and only then iterate on the prompt. The order matters: a prompt iterated against vibes will look great on the cases the writer chose to think about and fail on the cases they did not. For building the gold set, see six Q&A frameworks for building evaluation gold sets.
The judge prompt is the smallest, cheapest, most editable part of an evaluation pipeline. That is also why it is the part that gets the least scrutiny and produces the most surprise in production. Treat it the way you would treat any other piece of code that decides whether to ship: write it explicitly, version it, measure it against ground truth, and rewrite it when the measurement says you should.



