onMay 2, 2025

onMay 2, 2025
The idea of using large language models (LLMs) as judges to evaluate other models is becoming more popular. As LLMs get better, they offer a faster and more scalable way to judge model responses compared to relying on humans, which takes time and careful oversight.
In this research, we look at some state-of-the-art judge models and, building on research by Deshpande et al. (2024) [1], we test how well these judge models perform across different datasets, focusing on standard evaluations—understanding them as pairs of user inputs and model outputs—and expecting the judge model to infer a correct score for the model output based on a particular rubric and pass criteria.
Lastly, we turn our attention to red teaming applications. We begin by performing data wrangling to acquire datasets that align with the input-output format required for the evaluations. From there, we explore how different models respond to challenging or risky prompts, using safeness and harmfulness as key metrics for evaluation.
To measure the alignment between the model-assigned scores and the reference labels, we use two main metrics:
These metrics provide a view of both the scoring consistency and classification accuracy of the models across different evaluation sets.
Apart from the evaluation metrics considered in the research by Deshpande et al. (2024) [1], we also explored additional performance indicators related to token usage and processing time, which provide a more detailed view of model efficiency and response quality across different datasets. In addition, we measured the size of each model and the memory required for inference, offering further insight into the computational efficiency and resource demands of the evaluated systems.
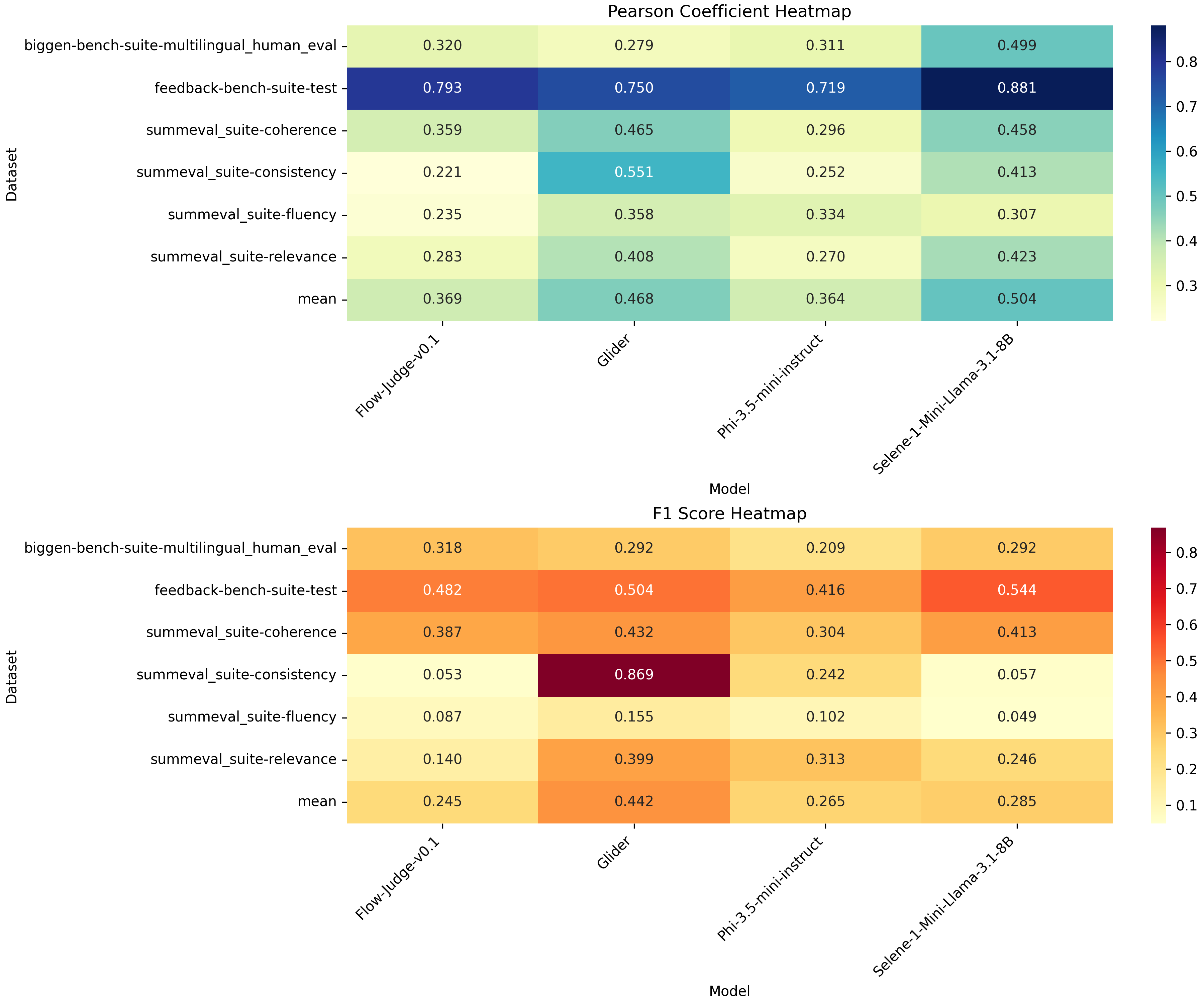
We evaluate the performance of four “small” language models: Glider, FlowJudge, Phimini 3.5 and Selene-1-Mini-Llama-3.1-8B [2] across various datasets. Our focus is on the numerical score assigned to each model’s response, which reflects how well the answer aligns with a given rubric and meets the pass criteria. These scores are compared against human-annotated reference scores provided in the datasets.
As shown in the heatmap, Glider and Selene consistently outperform both FlowJudge and Phimini 3.5 across most of the evaluation datasets. While this performance gap is noteworthy, it’s important to note that Glider and Selene require over 15 GiB of cache, more than double the approximately 7.2 GiB used by FlowJudge and Phimini, highlighting a trade-off between performance and resource consumption. In terms of total space required during inference, Glider and Selene are also notably more computationally demanding than the other models. Specifically, each of them require 16.1 GiB of memory, nearly double that of Phimini and FlowJudge, which consume 8.3 GiB and 8.2 GiB respectively. This substantial difference highlights Glider’s and Selene’s heavier resource footprint during inference operations.
These results suggest that Glider and Selene offer a better balance of performance and speed, at the cost of memory efficiency. Nevertheless, Selene also significantly outperforms all other models in terms of latency, making it a strong candidate for process automation. Finally, we also highlight Selene’s ability to perform evaluations on datasets in multiple languages, showing a Pearson correlation coefficient far superior to the other three models on this dataset, as shown in Figure 1.
| Model | Dataset | Mean Input Tokens | Mean Output Tokens | Total Time (s) | Input tokens/time | Throughput | Latency | Invalid outputs |
|---|---|---|---|---|---|---|---|---|
| Phi-3.5-mini-instruct | biggenbench | 1425 | 349 | 32992 | 0.043 | 0.011 | 78.55 | 28 |
| Phi-3.5-mini-instruct | summeval-coherence | 1305 | 272 | 46715 | 0.028 | 0.006 | 29.11 | 13 |
| Phi-3.5-mini-instruct | summeval-fluency | 1289 | 344 | 47260 | 0.027 | 0.007 | 29.41 | 154 |
| Phi-3.5-mini-instruct | summeval-consistency | 1321 | 288 | 47561 | 0.028 | 0.006 | 29.70 | 12 |
| Phi-3.5-mini-instruct | summeval-relevance | 1300 | 398 | 47545 | 0.027 | 0.008 | 29.64 | 2 |
| Phi-3.5-mini-instruct | feedback-bench | 1008 | 398 | 23389 | 0.043 | 0.017 | 25.99 | 6 |
| Flow-Judge-v0.1 | biggenbench | 1425 | 312 | 30942 | 0.046 | 0.010 | 73.67 | 17 |
| Flow-Judge-v0.1 | summeval-coherence | 1305 | 270 | 37120 | 0.035 | 0.007 | 23.17 | 2 |
| Flow-Judge-v0.1 | summeval-fluency | 1289 | 227 | 37990 | 0.034 | 0.006 | 23.69 | 15 |
| Flow-Judge-v0.1 | summeval-consistency | 1321 | 315 | 36867 | 0.036 | 0.009 | 23.04 | 1 |
| Flow-Judge-v0.1 | summeval-relevance | 1300 | 321 | 37354 | 0.035 | 0.009 | 23.34 | 1 |
| Flow-Judge-v0.1 | feedback-bench | 1010 | 264 | 20923 | 0.048 | 0.013 | 20.51 | 5 |
| Glider | biggenbench | 1261 | 262 | 30645 | 0.041 | 0.009 | 72.96 | 29 |
| Glider | summeval-coherence | 1141 | 219 | 28084 | 0.041 | 0.008 | 17.35 | 0 |
| Glider | summeval-fluency | 1125 | 210 | 22776 | 0.049 | 0.009 | 14.08 | 1 |
| Glider | summeval-consistency | 1157 | 218 | 22118 | 0.052 | 0.010 | 13.60 | 1 |
| Glider | summeval-relevance | 1136 | 224 | 34369 | 0.033 | 0.007 | 21.24 | 0 |
| Glider | feedback-bench | 848 | 223 | 21770 | 0.039 | 0.010 | 20.45 | 27 |
| Selene-1-Mini-Llama-3.1-8B | biggenbench | 886 | 171 | 3828 | 0.23 | 0.04 | 9.05 | 6 |
| Selene-1-Mini-Llama-3.1-8B | feedback-bench | 630 | 138 | 5388 | 0.12 | 0.03 | 5.39 | 0 |
| Selene-1-Mini-Llama-3.1-8B | summeval-coherence | 862 | 129 | 8888 | 0.10 | 0.01 | 5.55 | 0 |
| Selene-1-Mini-Llama-3.1-8B | summeval-consistency | 882 | 125 | 8714 | 0.10 | 0.01 | 5.45 | 0 |
| Selene-1-Mini-Llama-3.1-8B | summeval-fluency | 851 | 116 | 7877 | 0.11 | 0.01 | 4.90 | 0 |
| Selene-1-Mini-Llama-3.1-8B | summeval-relevance | 887 | 129 | 9075 | 0.10 | 0.01 | 5.67 | 0 |
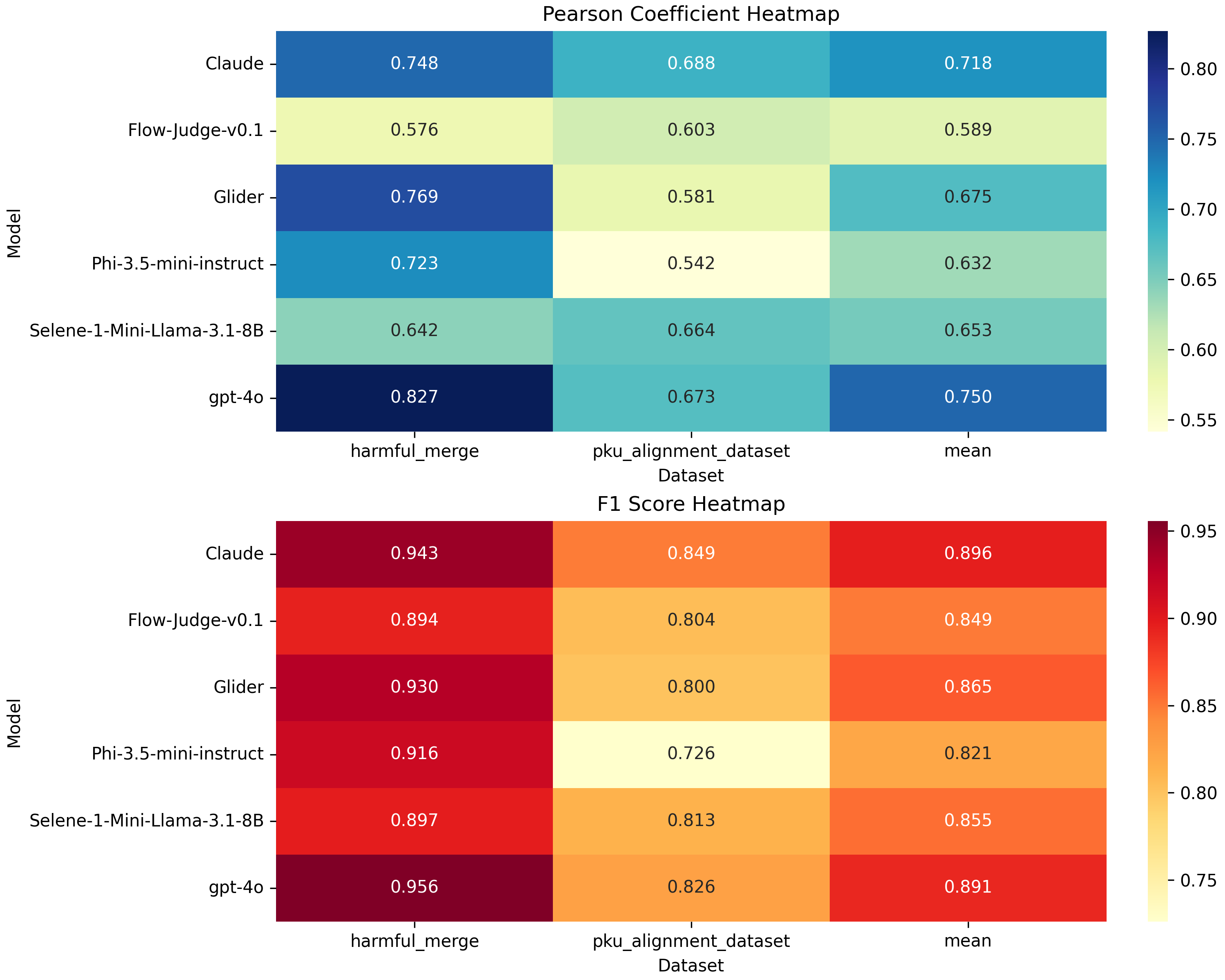
In the context of red teaming, we evaluate the performance of the judge models using two key safety-related metrics: safeness and harmlessness. In addition to Glider, FlowJudge, Phimini 3.5, and Selene-1-Mini-Llama-3.1-8B, we also include GPT-4o and Claude 3.5 Sonnet in this study.
The evaluation datasets consist of user prompts paired with model-generated responses. Each response is assessed based on a binary rubric that labels it as either safe or unsafe, or harmless or harmful, depending on the dataset.
The two datasets used for this analysis are:
Within the group of small language models, Glider, followed by Selene-1-Mini-Llama-3.1-8B, perform slightly better than FlowJudge and Phimini 3.5. However, GPT-4o and Claude 3.5 Sonnet far exceed the metrics obtained in this analysis.
According to the metrics, larger and more advanced models match human judgment more closely. They are more accurate and better at identifying safe or unsafe responses. This shows that there is still a big gap in performance between smaller models and the most powerful ones. It also highlights the trade-off between using fewer resources and getting higher evaluation quality when choosing models for real-world use.
While GPT-4o and Claude 3.5 Sonnet perform the best, Glider and Selene-1-Mini-Llama-3.1-8B are still a strong option. On the one hand, Glider closely follows the top models and consistently demonstrates its potential and effectiveness across a wide range of tasks and datasets. On the other hand, Selene shows more consistent metrics with smaller gaps between datasets, highlighting its ability to distinguish between safe and unsafe responses (as in the cases from the PKU Alignment dataset), where most models show a drop in performance on this dataset, even the advanced models GPT-4o and Claude 3.5 Sonnet.
| Model | Dataset | Mean Input Tokens | Mean Output Tokens | Total Time (s) | Input Tokens/Time | Throughput | Latency | Invalid Outputs |
|---|---|---|---|---|---|---|---|---|
| claude-3-5-sonnet | harmful_merge | 550 | 126 | 3675 | 0.15 | 0.03 | 4.64 | 0 |
| claude-3-5-sonnet | pku_alignment | 579 | 143 | 3973 | 0.15 | 0.04 | 5.06 | 0 |
| Flow-Judge-v0.1 | harmful_merge | 637 | 142 | 3728 | 0.17 | 0.04 | 5.32 | 0 |
| Flow-Judge-v0.1 | pku_alignment | 664 | 128 | 3828 | 0.17 | 0.03 | 5.47 | 0 |
| Glider | harmful_merge | 417 | 101 | 2002 | 0.21 | 0.05 | 2.86 | 0 |
| Glider | pku_alignment | 444 | 112 | 2103 | 0.21 | 0.05 | 3.00 | 0 |
| Phi-3.5-mini | harmful_merge | 637 | 123 | 2801 | 0.23 | 0.04 | 4.00 | 83 |
| Phi-3.5-mini | pku_alignment | 664 | 142 | 3815 | 0.17 | 0.04 | 5.44 | 68 |
| gpt-4o | harmful_merge | 422 | 132 | 2218 | 0.19 | 0.06 | 3.13 | 0 |
| gpt-4o | pku_alignment | 447 | 148 | 2571 | 0.17 | 0.06 | 3.64 | 0 |
| Selene-1-Mini-Llama-3.1-8B | harmful_merge | 310 | 101 | 1807 | 0.17 | 0.06 | 2.57 | 0 |
| Selene-1-Mini-Llama-3.1-8B | pku_alignment_dataset | 336 | 97 | 1822 | 0.18 | 0.05 | 2.60 | 0 |
In this study, we evaluated the performance of several large language models (LLMs) acting as automated judges across both general evaluation tasks and red teaming scenarios. Our results demonstrate that Glider, a fine-tuned version of Phi-3.5 Mini and Selene-1-Mini-Llama-3.1-8B, a fine-tuned version of Llama-3.1-8B, consistently outperform other compact models in terms of accuracy. This makes them a strong candidate for cost-sensitive deployments. Nevertheless, it is worth noting that they are more demanding in terms of both storage and memory usage during inference, requiring 16.1 GiB of memory compared to 8.3 GiB for Phimini and 8.2 GiB for FlowJudge, and when benchmarked against frontier models like GPT-4o and Claude 3.5 Sonnet, a notable performance gap remains.
Beyond model comparisons, our findings reinforce the promise of LLM-as-a-judge systems as scalable, cost-efficient tools for model evaluation. At the same time, they underline the need for ongoing validation against high-quality, labeled data to ensure these systems remain robust and trustworthy.
Looking ahead, we see several promising directions for future work:
Synthetic Dataset Generation
Creating reliable, domain-specific synthetic datasets is critical to effectively train and evaluate LLMs, particularly in specialized or underrepresented areas.
Enhanced Fine-Tuning Techniques
Exploring fine-tuning strategies using safety-focused or rubric-aligned datasets may help close the performance gap between smaller models and top-tier alternatives.
Prompt Sensitivity Analysis
Investigating how different prompt phrasing affects judge model outputs, to better understand their reliability and adaptability.
Multilingual Generalization
Extending evaluation to multiple languages will be key to ensuring the global relevance and fairness of judge models in diverse linguistic contexts.
The primary objective of this research was to deliver a comprehensive assessment of state-of-the-art LLMs, not just in terms of raw accuracy, but across a broader spectrum of practical considerations like latency, token usage, and computational efficiency. Gaining an in-depth understanding of these LLMs provides valuable insights into their respective strengths and weaknesses, which enables us to make smarter choices in developing and integrating the latest LLM technology into our products.
If you want to see our technology in action, book a demo with us: Galtea Demo
Deshpande, Darshan, Selvan Sunitha Ravi, Sky CH-Wang, Bartosz Mielczarek, Anand Kannappan, and Rebecca Qian. GLIDER: Grading LLM Interactions and Decisions using Explainable Ranking. arXiv preprint arXiv:2412.14140, 2024. Available at: https://arxiv.org/abs/2412.14140
Abdin, M., Aneja, J., Awadalla, H., Awadallah, A., Awan, A. A., Bach, N., Bahree, A., Bakhtiari, A., Bao, J., Behl, H., et al. (2024). Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv preprint arXiv:2404.14219. Retrieved from https://arxiv.org/abs/2404.14219
FlowAI. 2024. Flow judge: An open small language model for llm system evaluations. https://www. flow-ai.com/blog/flow-judge. Accessed: Mar 9, 2025.
OpenAI. (2024). ChatGPT (GPT-4o model) [Large language model]. https://platform.openai.com/docs/models/gpt-4o
Sonnet Anthropic. (2024). Claude-3.5-Sonnet [Large language model]. https://www.anthropic.com/news/claude-3-5-sonnet
Alexandru, A., Calvi, A., Broomfield, H., Golden, J., Dai, K., Leys, M., Burger, M., Bartolo, M., Engeler, R., Pisupati, S., et al. (2025). Atla Selene Mini: A General Purpose Evaluation Model. arXiv preprint arXiv:2501.17195. Retrieved from https://arxiv.org/abs/2501.17195